Self Learning Kubernetes: Persistent storage (Pt. 3)
Introduction
Most of the articles and tutorials I came across while attempting to learn Kubernetes had to do with setting it up in a cloud environment. My goal was to self host everything so that I could get a better understanding of how Kubernetes worked and so I could have a foundation for working on internal projects that would closely resemble an enterprise environment. Data storage persistence with Kubernetes involves several concept understandings which is what I'll be briefly discussing along with a technology called Longhorn that makes local persistence storage a breeze.
Kubernetes Storage Concepts
There are a few concepts in Kubernetes that you need to know about in order to understand how storage within Kubernetes works.
- CSI (Container Storage Interface): CSI is an API standard that standardizes how storage providers integrate with Kubernetes. In this this case, Longhorn is a CSI-compliant implementation which allows on-premises storage. More information on CSI can be found here: https://kubernetes-csi.github.io/docs/
- Volumes: A volume is a directory, possibly with some data in it, which is accessible to the containers in a pod. How that directory comes to be, the medium that backs it, and the contents of it are determined by the particular volume type used. Source: https://kubernetes.io/docs/concepts/storage/volumes/
- Persistent Volume Claims: "A Persistent Volume Claim (PVC) in Kubernetes is like a request for storage by an application.
Here’s a simple analogy: Imagine you’re living in an apartment building (the Kubernetes cluster), and you need a storage unit (persistent storage). You don’t go and grab the storage space directly; instead, you make a request to the building manager (Kubernetes) for a specific size and type of storage. This request is the PVC. The building manager then finds an available storage unit (Persistent Volume or PV) that matches your request and gives you access to it." -ChatGPT
Honestly the way ChatGPT worded this was perfect. It's a way for the developers to request the storage they need. This wording is what made it click for me and you'll see why in a moment.
Why the multiple layers (Volumes, Persistent Volume Claim, Storage Class)?
There are multiple technology teams in globally sized enterprises each with their own responsibilities to keep the organization working as intended. With Kubernetes you can split responsibilities up.
For example, as a developer I want 50GB available for my application. I don't care about the underlying implementation details, just give me 50GB.
Likewise, as a devops engineer I want to deploy an application using CI/CD. I may not want to know about the storage medium and other facets, my job is to setup Jenkins, TeamCity, or any other CI/CD pipeline to get the application deployed. In this case, I may just need to create the helm chart that specifies the image used and the location from which to find the image. I don't care about the storage needed in this example as the developer has specified everything the application needs.
One more example would be the Infosec team requiring that certain network policies and role based access is in place. They can setup the roles and policies needed and may even work with the networking team for setting up the networking between the various applications.
Local Storage and Longhorn
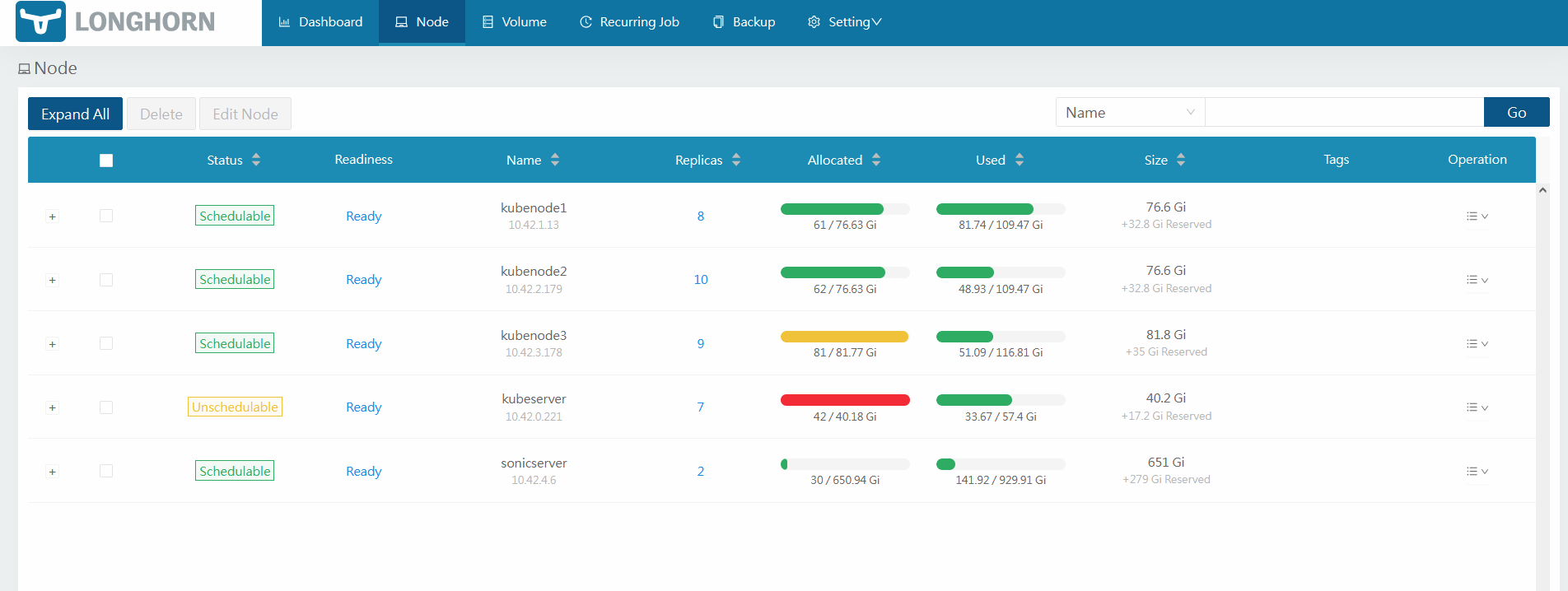
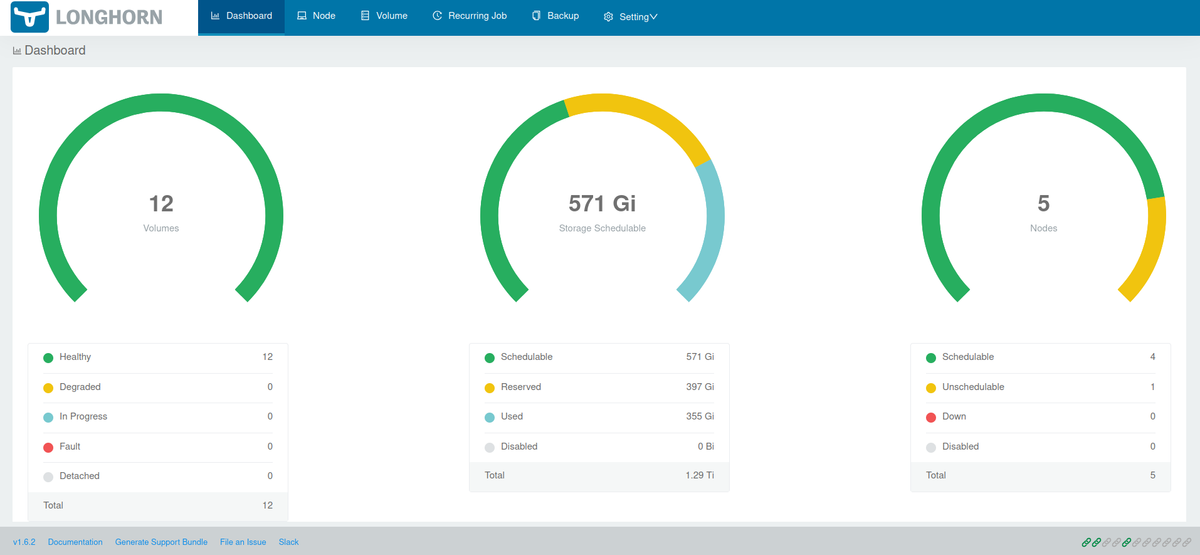
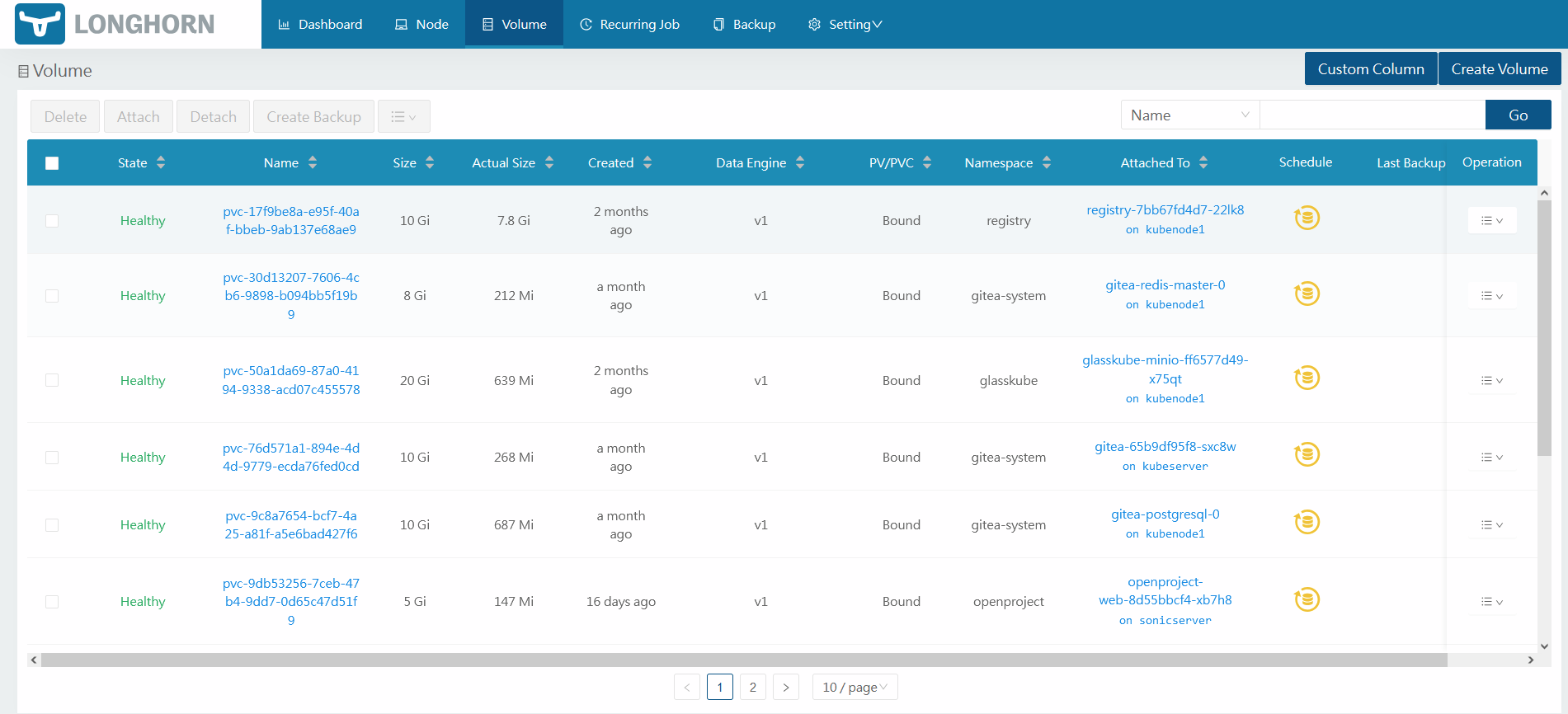
Since I want to keep all my data within my network, I chose to use Longhorn as my storage class. By doing this, Longhorn will automatically create persistent volumes and replicas of those volumes spread across nodes in my cluster. Keeping in mind that nodes are physical machines, you can see how Longhorn has a layer of redundancy. It spreads copies of the data to different nodes depending on the number of replicas and backups that you want. Likewise, if a pod is removed, the data will still exist on those nodes meaning you have persistent storage and redundancy. Cool right? No need for AWS S3 for our homelab. Keep in mind that a proper backup plan should be done for production environments such as offsite backups, tape backups, multiple copies etc.
Conclusion
There are other features and options for your use with Longhorn. This post was a very brief overview of how storage persistence works in Kubernetes and how enterprise organizations might use Kubernetes with their teams. I highly recommend playing with a cluster hands on with Longhorn to see what issues you might face and how it works. In addition to storing data on prem, Longhorn can also backup to cloud storage such as AWS S3 so check it out!